

Will somebody earn over 50k a year?
This blog is about building a model to classify people using demographics to predict whether a person will have an annual income over 50K dollars or not.
The dataset used in this experiment is the US Adult Census Income Binary Classification dataset, which is a subset of the 1994 Census database, using working adults over the age of 16 with an adjusted income index of > 100.
This blog is inspired on the Sample 5: Binary Classification with Web Service: Adult Database from the Cortana Intelligence Gallery.
The experiment corresponding to this blog can be found on and downloaded from the Cortana Intelligence Gallery.
We will walk through the model in 10 steps, with an additional BONUS step for extra insights.
Model Overview
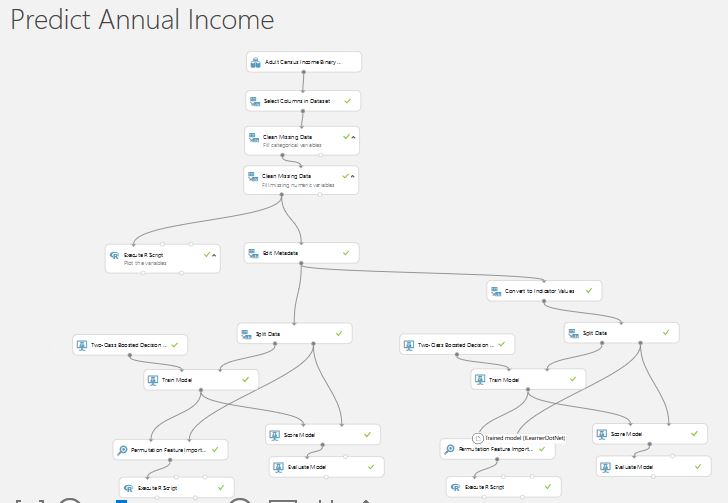
For a better view, please download the experiment and open it in Azure Machine Learning Studio.
Step 1: Getting the data
This data is directly available from the Azure Machine Learning sample datasets.
We can get some quick data insights by using the standard visualization from the Azure Machine Learning studio:
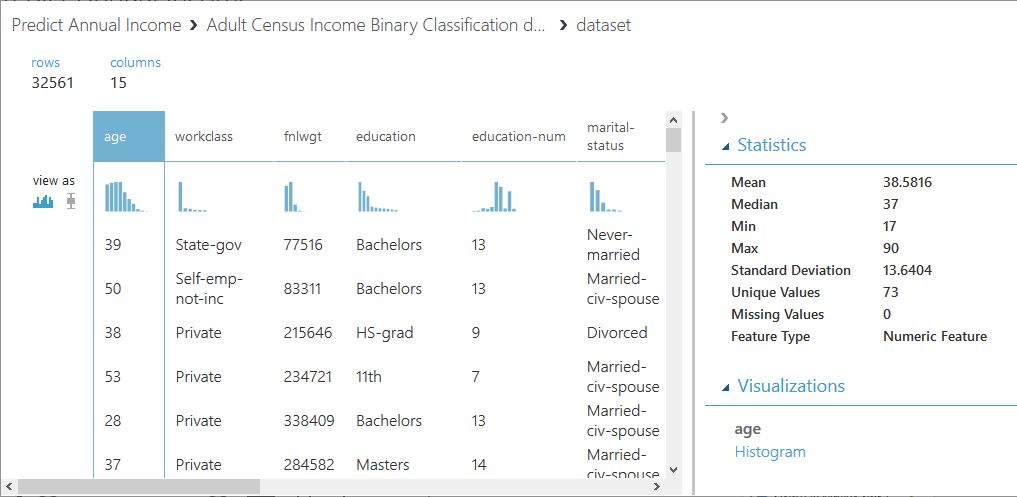
Step 2: Select required columns
First, we observe that “education” and “education-num” are equivalent. Based on the nature of the other variables, we decide to delete “education-num” and continue with “education”. Besides, as explained on the UCI Machine Learning Repository, we deleted the variable “fnlwgt”, which is a weighting variable that should not be used in classifiers.
Step 3: Clean missing data
For the categorical variables, we fill-out the missing values with the value “other”. For the numerical variables, we replace the missing values with the median, as the mean would give a very distortionate view. Look i.e. at the variable “capital-gain”, where the mean is 1078 and the median 0. We end up with 1 dependent variable “income” and 12 predicting variables: “age”, “workclass”, “education”, “marital-status”, “occupation”, “relationship”, “race”, “sex”, “captital-gain”, “capital-loss”, “hours-per-week”, and “native-country”.
Step 4: Inspect the data
With the “Execute R Script” module we write a short script to show some basic graphs to better understand the available data.
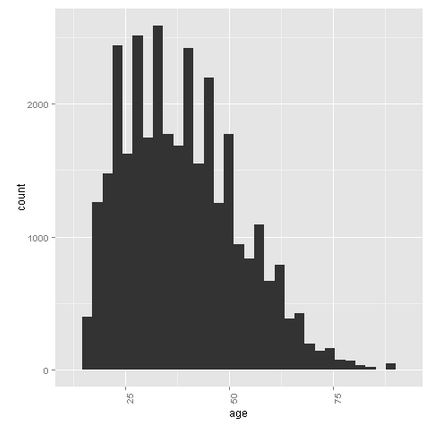
Age
The selection on the original database excludes people younger than 16. On average (both mean and median) one is 37/38 years old. However, there are quite some people over 75 that are stil working.
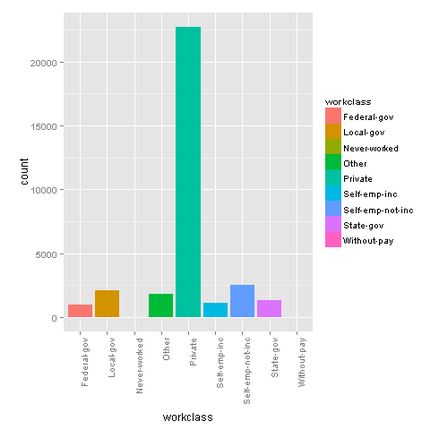
Workclass
Most of the people of this sample are from the private sector.
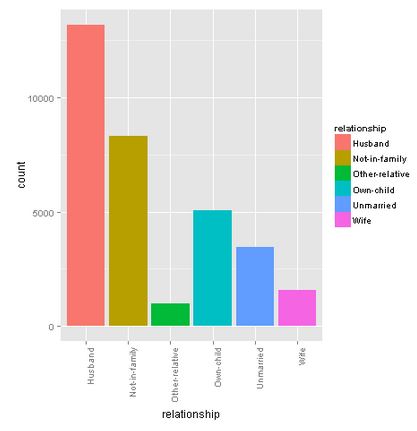
Education
Most of the people have a high-school degree or higher.
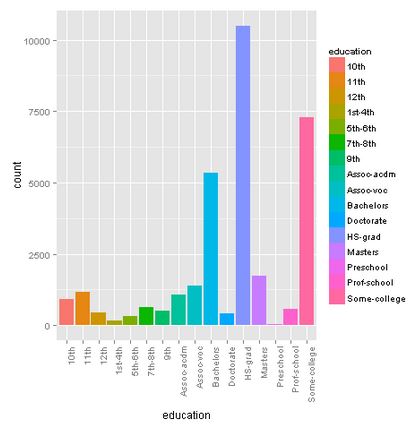
Marital-status
Many people are married (married-civ-spouse), followed by never-married people.
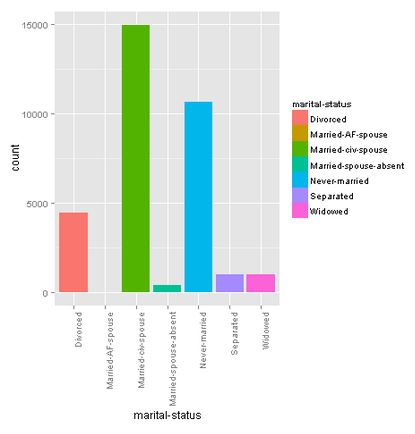
Occupation
There is quite a diversity among the occupation. We found 14 occupancies, and added an extra “other” option for those who left this field empty.
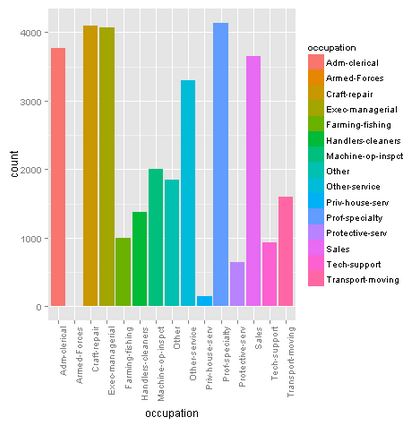
Relationship
Most of the people are found in a relationship as husband. This makes sense if we look at the gender distribution later on.
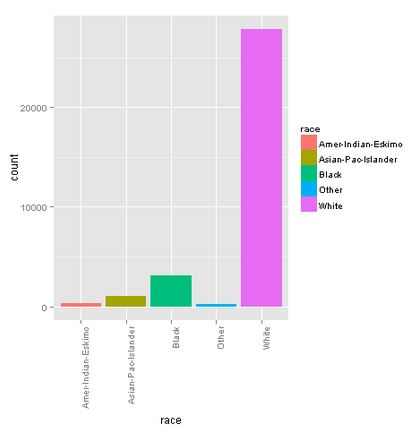
Race
The majority of this sample exists of white people.
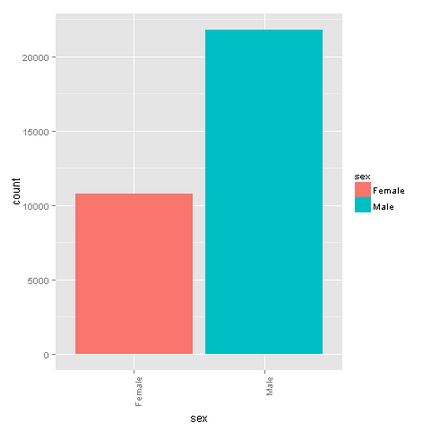
Sex
The male-female ratio is around 2:1. This also explains the high “husband” value for the “relationship” variable.
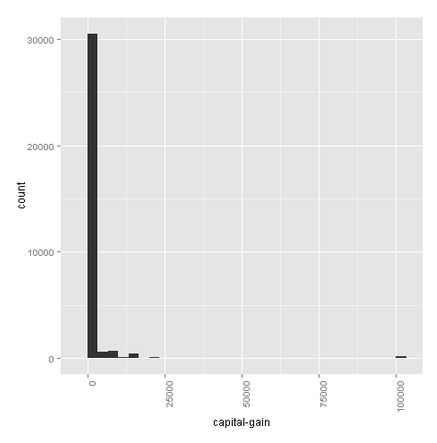
Capital-gain
There are very little people that have capital gains.
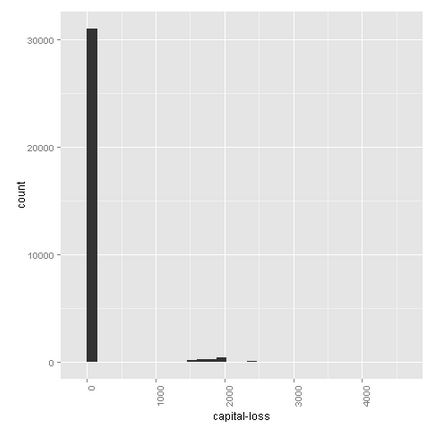
Capital-loss
There are very little people that have capital losses.
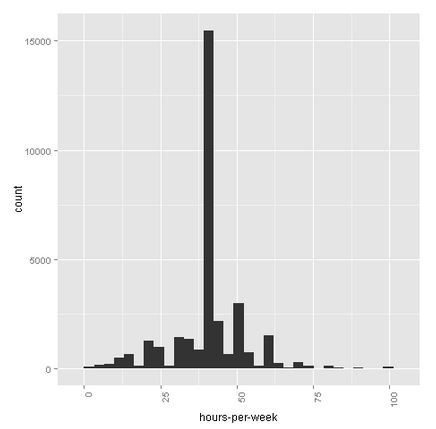
Hours-per-week
On average, one works 40 hours a week, although we see some very busy people with 100-hour weeks.
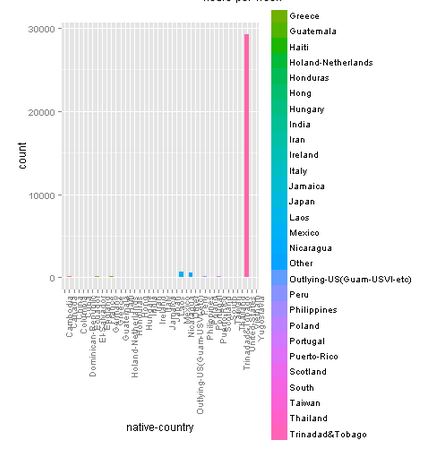
Native-country
This graph is not really clear in this environment. When running it in R, we can clearly see that most of the people are coming from the United States (the big pink bar).
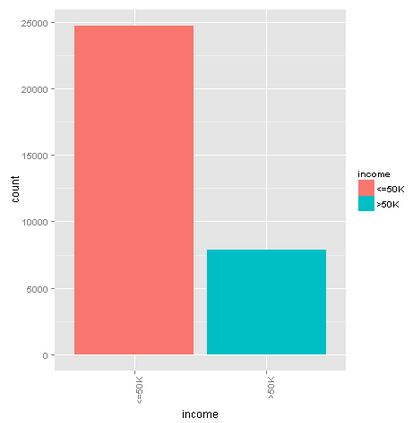
Income
76% of the sample earns less than 50K dollar a year, and 24% more. We will take this into account when splitting the data into a training and test set. We also set a seed to make this blog reproducible.
Step 5: Take care of the variable types
We make sure that we set the categorical variables from string to categorical. We will use this later on.
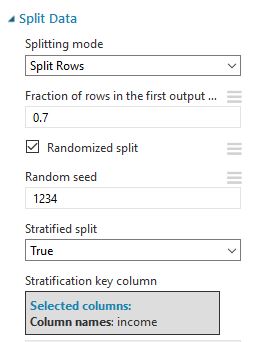
Step 6: Split the dataset into a training and a test set
We split the dataset into a training and a test set, taking the income distribution into account, using a stratified split.
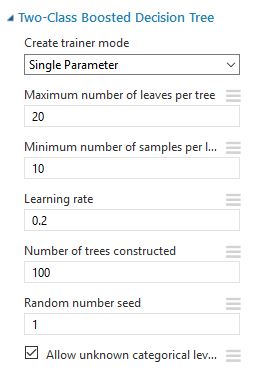
Step 7: Train the basic model
For this experiment, we use the standard settings to train the model with a Two-Class Boosted Decision Tree algorithm. These settings can be improved by using the Tune Model Hyperparameters module to train the model.
Step 8: Evaluate the Feature Importance
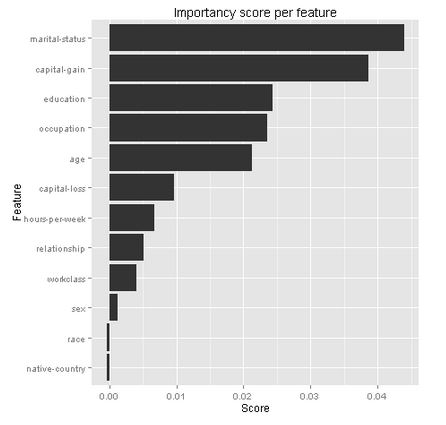
With the Feature Importance module, we can obtain the importance of the features. The scores are based on how much the performance of the model changes when the feature values are randomly shuffled. The scores that the module returns represent the change in the performance of a trained model, after permutation.
With the help of an R script, we can display the scores of the features.
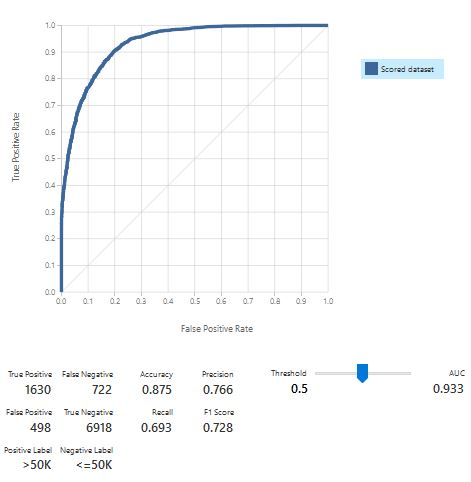
Step 9: Score the test data
With the trained model, we score the test data.
Step 10: Evaluate the model
The results using the standard settings are already fairly good!
BONUS: Continuation of the Feature Importance
As we have seen in step 8, we have a better understanding of the importance of every feature. However, it does not tell you if there is a specific value of that feature that drives this score. We can find this out by transforming the categorical variables into the so-called dummy variables, where every category will become a seperate column. I.e. if we look at “marital-state” there are 7 options: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, and Married-AF-spouse. With the Convert to Indicator Value module, we can changed these into 7 different variables, where every variable represents a category.
We repeat step 6 to 10, maintaining all the settings, but now we will gain insight regarding feature importance:
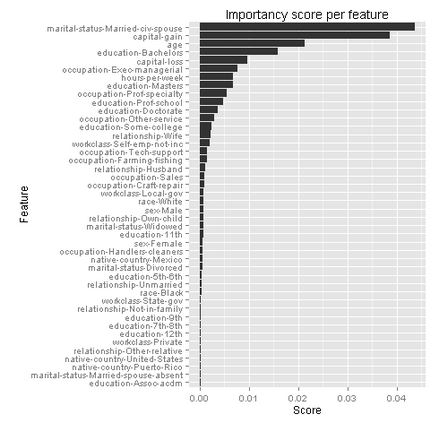
Before we only knew that “marital-status” had the highest feature importance score, but now we can also see, that it was being in a “marital-status-Married-civ-spouse” that made the difference.
Money makes money?
In order to predict whether somebody will earn over 50K dollars we’ve seen that their marital status is important. But our second most important feature is “capital-gains”. So money makes money?! It would be interesting to figure that out in future research.
I hope you enjoyed this experiment and I’m looking forward to hearing your opinion!
Related Research: Kohavi, R., Becker, B., (1996). UCI Machine Learning Repository http://archive.ics.uci.edu/ml. Irvine, CA: University of California, School of Information and Computer Science